<!DOCTYPE html> <html data-bs-theme="light">
<head> <meta charset="utf-8">
<script async src="https://www.googletagmanager.com/gtag/js?id=G-NG21EXTML9"></script> <script> window.dataLayer = window.dataLayer || []; function gtag(){dataLayer.push(arguments);} gtag('js', new Date());
gtag('config', 'G-NG21EXTML9'); </script> <meta name="viewport" content="width=device-width, initial-scale=1.0, shrink-to-fit=no"> <title>SpeakHDL</title> <meta name="keywords" content="FPGA, FPGA Prototyping, FPGA Tool, Voice Coding, procedural programming, FPGA Easy, VHDL, FPGA for beginners"> <meta name="description" content="A practical FPGA design tool that combines procedural programming using native VHDL with command-based programming"> <link rel="icon" type="image/png" sizes="16x16" href="assets/img/logo/favicon-16x16.png"> <link rel="icon" type="image/png" sizes="32x32" href="assets/img/logo/favicon-32x32.png"> <link rel="icon" type="image/png" sizes="192x192" href="assets/img/logo/android-chrome-192x192.png"> <link rel="icon" type="image/png" sizes="512x512" href="assets/img/logo/android-chrome-512x512.png"> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.1/dist/css/bootstrap.min.css"> <link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.12.0/css/all.css"> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css"> <link rel="stylesheet" href="assets/fonts/fontawesome5-overrides.min.css"> <link rel="stylesheet" href="https://unpkg.com/@bootstrapstudio/bootstrap-better-nav/dist/bootstrap-better-nav.min.css"> <link rel="stylesheet" href="assets/css/doxy-override.css"> <link rel="stylesheet" href="assets/css/Footer-Basic.css"> <link rel="stylesheet" href="assets/css/Login-Form-Clean.css"> <link rel="stylesheet" href="assets/css/banner.css"> <link rel="stylesheet" href="assets/css/examples.css"> <link rel="stylesheet" href="assets/css/speakhdl-styles.css"> </head>
<body> <nav class="navbar navbar-expand-md sticky-top navbar-top theme-outline navbar-light" id="my-nav">
</nav> <article>

Strategy for API Development
Our challenge in trying to a creating a useable API for FPGA hardware development is threefold:
- Understand the synthesizable HDL language features we have at our disposal
- Organize the data structures that we create in such a way that the end user can become the most productive
- Create procedure calls based on operations that can be used as building blocks in system design
Because, creating an API is more of an art than a science, there will be instances where we could approach our data structuring in multiple ways. Since our overall goal is to be come more productive FPGA developers, we describe the strategy we use for creating the API for our design pattern.
- Treat everything as a synchronous state machine
- Ensure the default behavior is the most useful behavior
- Prefer indexing an array over a creating a new signal
- Use aliases for readability
-
Use integer data types for index, count, and state
- Have productivity come for free
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside>
Everything Is A Synchronous State Machine
To motivate our rationale as to why we should treat an application module as a state machine, let's start with an example where an application module has exactly one input pin that is used as the count enable to a framework counter.
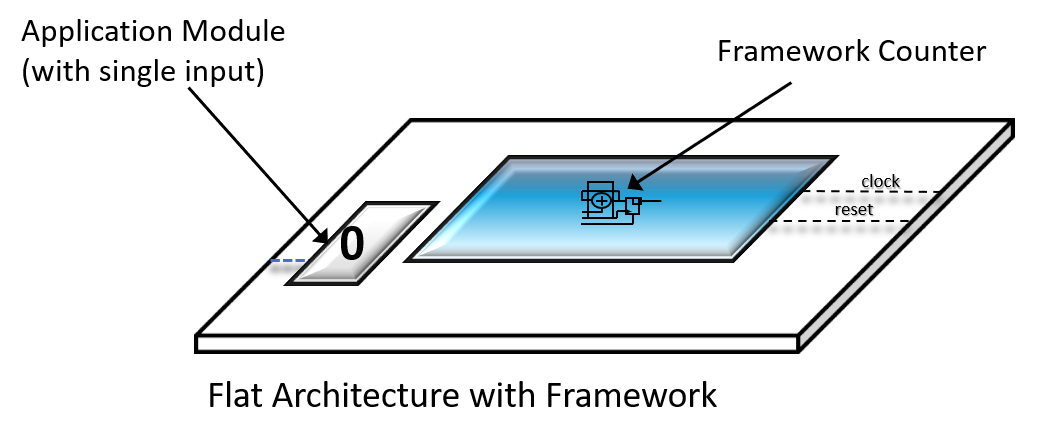
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex flex-row align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex flex-row align-items-center aside-xxx">
Added Value
</aside>
The Default Behavior Should Be the Most Useful Behavior
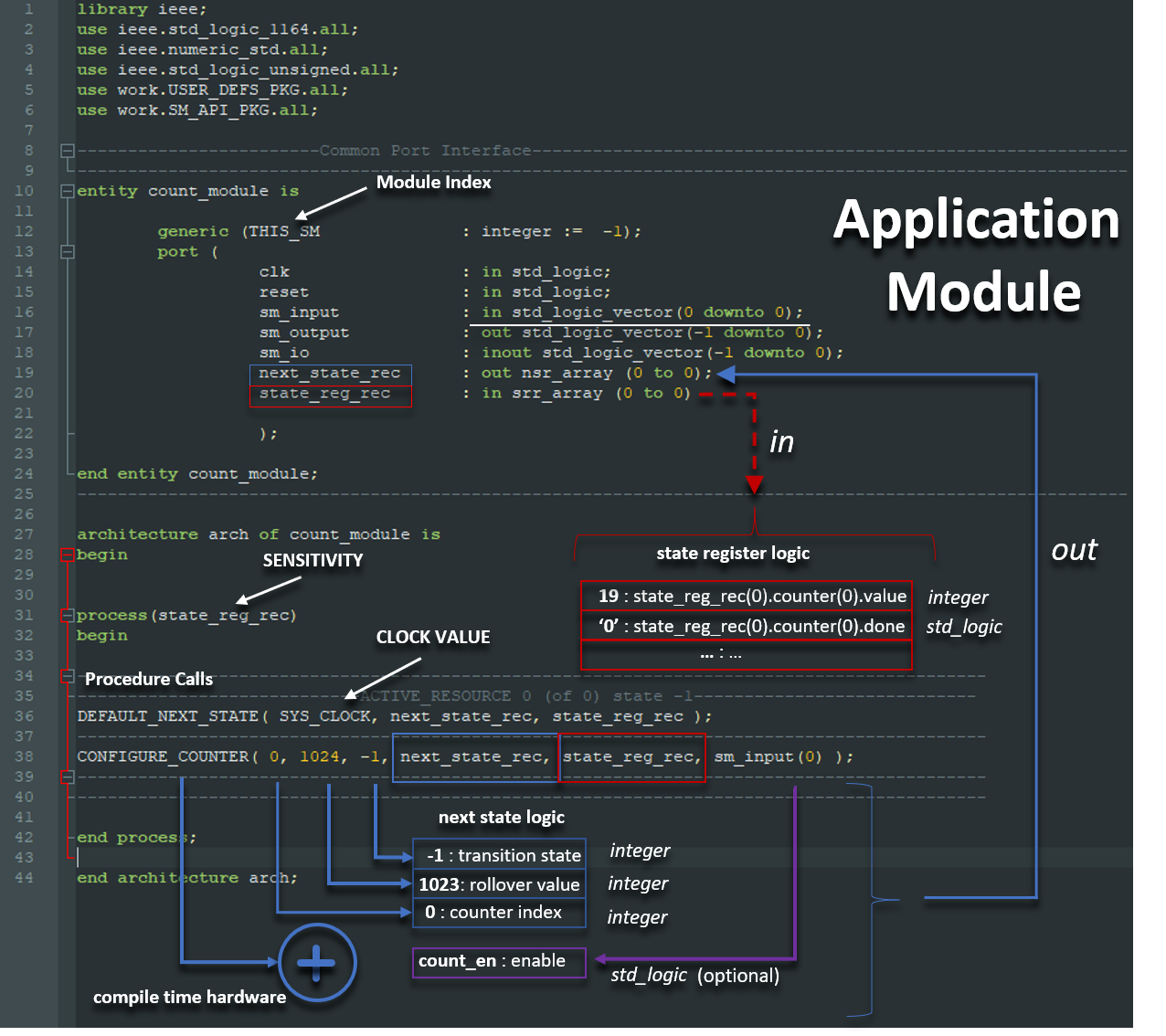
When creating our API, using default arguments, we try to prevent things like flatlining from happening. That being said, lets take another look at the 'configure_counter' procedure call and this time lets imagine we forgot to wire sm_input(0) to the last parameter.
 If we were to compile and simulate the design, the code may not work as desired, but the counter would still do something. We would see it free running and rolling over as it counts from 0 to 1023. Once we see this, it will be easy to know what we should fix. That behavior occurs because our choice was to make the default value for the count_en to be '1', and the default value for the rollover_en to be '1'.
If we were to compile and simulate the design, the code may not work as desired, but the counter would still do something. We would see it free running and rolling over as it counts from 0 to 1023. Once we see this, it will be easy to know what we should fix. That behavior occurs because our choice was to make the default value for the count_en to be '1', and the default value for the rollover_en to be '1'.Continuing with our design pattern strategy to treat 'everything as a state machine', the default state of every hardware component inferred by procedure call is made up of two parts:
Added Value
</aside>
- The default values of the procedure call optional arguments (if any)
- The framework default values set by the 'default_next_state' procedure call.
Added Value
</aside>
Alias is Your Friend
Added Value
</aside>
Integer Index, Count, and State
Added Value
</aside>
Looking at the third parameter, we have set the transition state to -1. The meaning of -1 in this context is we wish for the counter to just count, but not 'do anything' when the counter expires. Because the state machine states have the integer data type, we 'could' on the other hand, configure a state machine to change state when the rollover occurs.
Added Value
</aside>
Productivity Should Come For Free
- You don't see clock or reset being used
- You don't see a signal declaration
- You don't see an 'if-then-else' statement
When a counter resets, shouldn't the count go to zero? When it increments, wouldn't it be on the rising edge? Since the motivation for our design pattern is to increase design productivity, we should not have to write extra code to specify some assumed operation. If its expected behavior, you should get that for free.
Another productivity enhancing byproduct that occurs when using the design pattern, is a substantial decrease in the number of 'infrastructure related signals' you need to declare. A while back in our discussion, we mentioned that the data structures that are used by the design pattern were large and that how the long names can be annoying. But here is the up side. Those long state_reg_rec signal names come from the framework as an input to the application module port. That means we get access to a large data structure that we did not need to declare as a signal in our code. We can just start coding our application module and pick off the portions of the state register that we would like to use and start using them. Any portions of state register we use gets kept, and the rest of the large data structure just gets synthesized away.
Added Value
</aside>
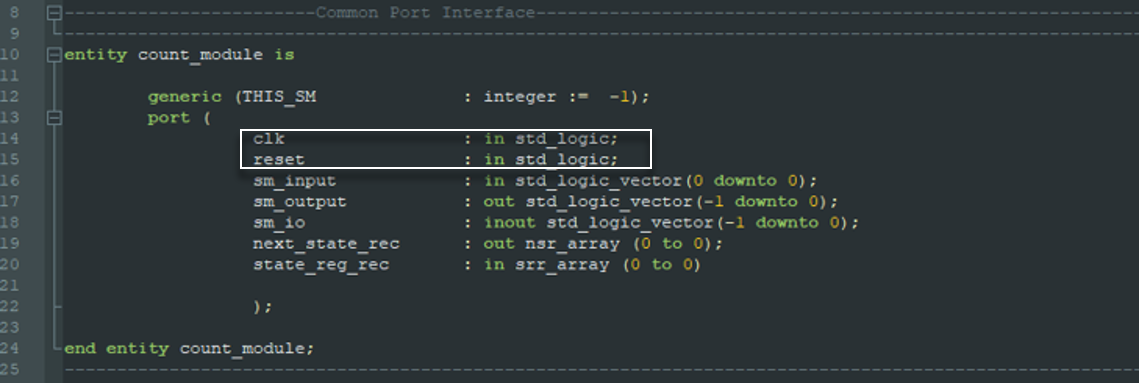
The takeaway here is that, the use of the API calls to infer hardware from the framework is optional. Productivity from infrastructure reuse happens when an application module can take advantage of the design pattern handing a general case not every specific use case. Once a VHDL entity conforms to the fixed port interface and becomes an application module, that module gets access to framework resources whether it uses them or not. If the application module chooses to use API calls to infer hardware, it is essentially productivity that the module gets for free.
Added Value
</aside>
</section> <section>
Synchronous Communication Between Application Modules
Back when we made our modifications to the software version of the facade design pattern, we added the ability to logically identify each application module by use of an integer. Without delving into all the details, this is how the logical identifier comes into play.
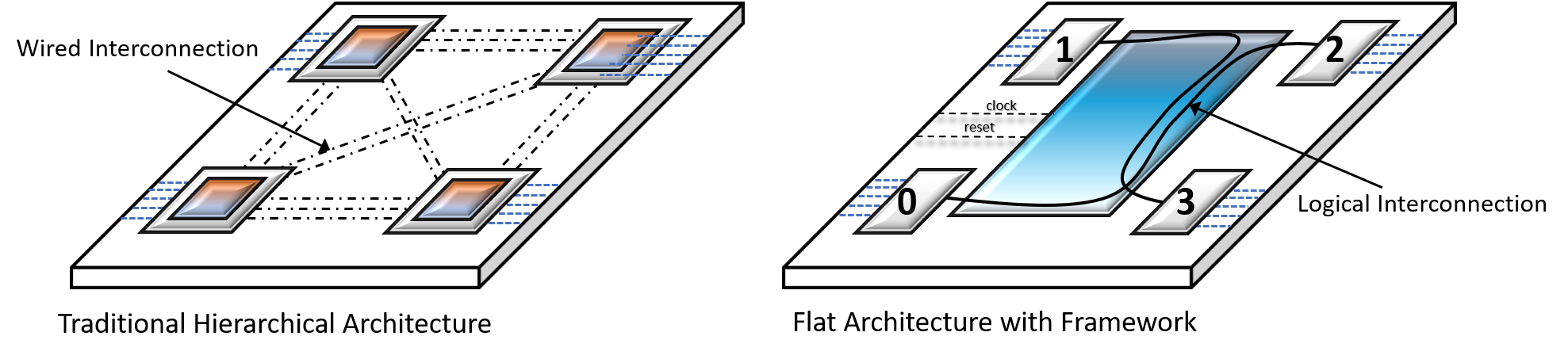
-
Point to Point Communication (Data Channel)
⇄ Fifo Communication
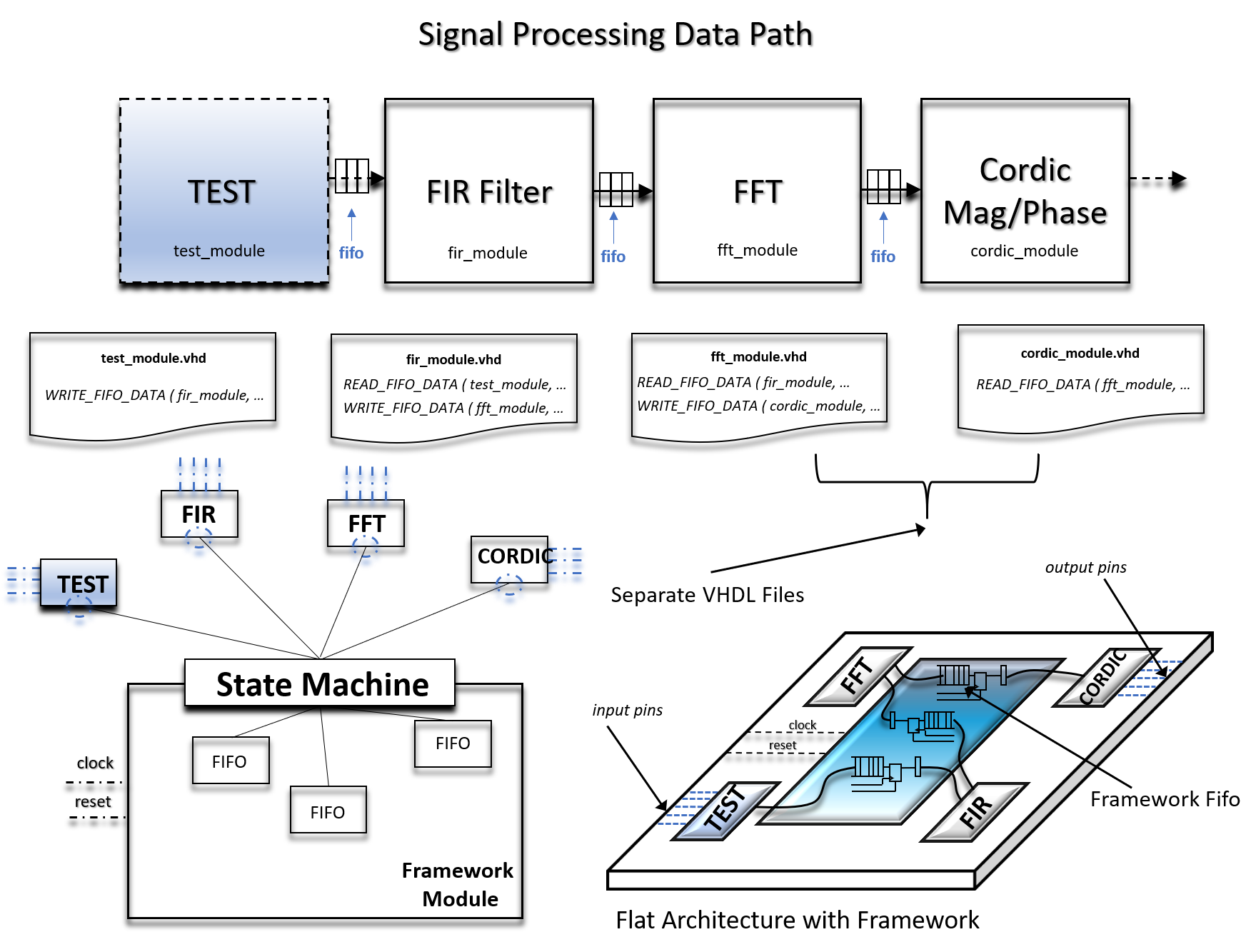
⇄ Data Exchange Register - Shared Control Register (Control Channel)
- Event Broadcasting
Added Value
</aside>
Point to Point Data Path Communication
Fifo Communication
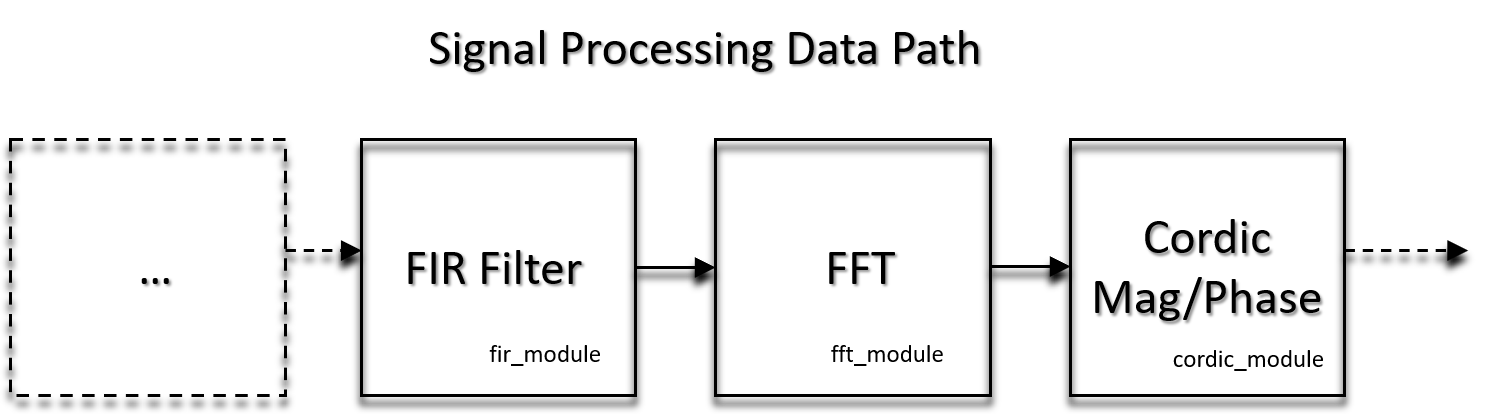
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside>
Data Exchange Register
Added Value
</aside>
Shared Control Register
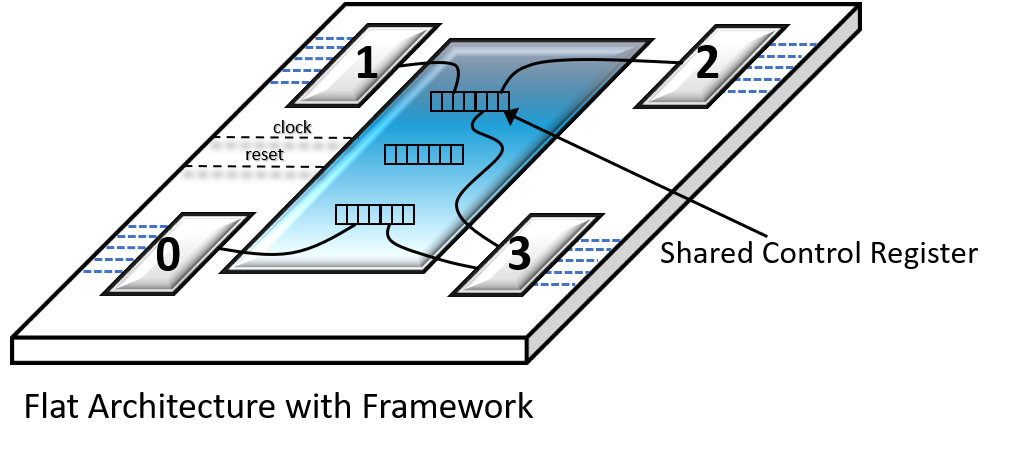
Added Value
</aside>
Event Broadcasting
In general, using 'if statements' are frowned upon when using the design pattern. Because of this, when a transition is needed in response to an event, to make the intent clear, the design pattern has specific API calls to raise and/or event or respond to an event.
Added Value
</aside>
</section> <section>
Productivity While Testing
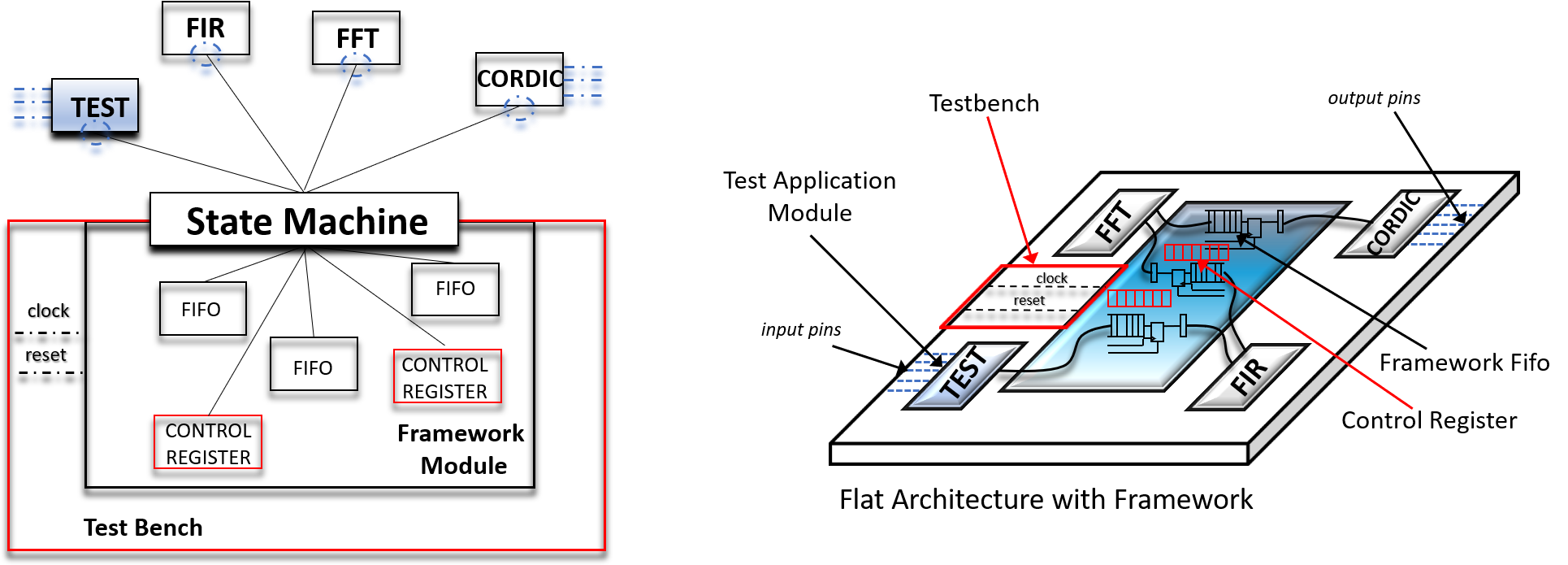
In order to simulate an FPGA design that uses our design pattern, we have essentially two options.
- Use a testbenches file to instantiate the top level design and drive application module I/O pins with the testbench file
- Use a testbenches file to instantiate the top level and drive signals internally from the API
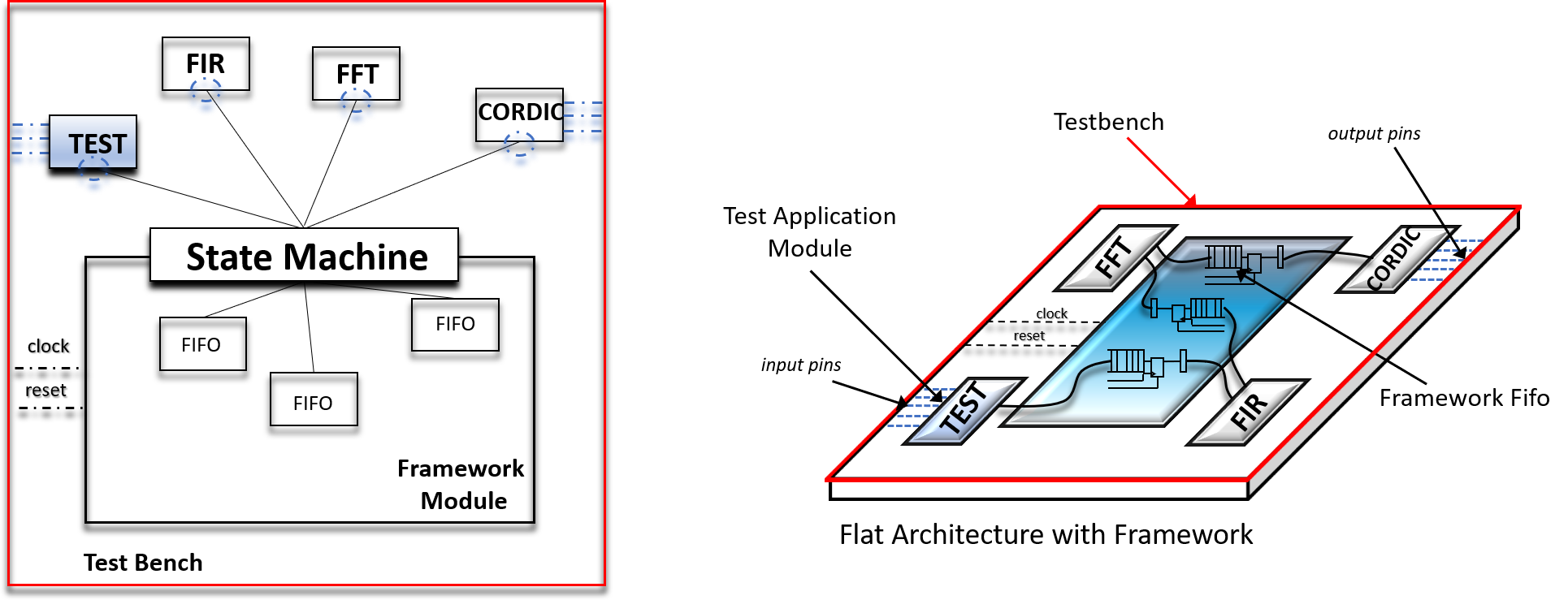
Added Value
</aside>
</section> <section> <header class="justify-content-center banner-header theme-outline" dx-block="block">
VHDL Code Structure Using the Design Pattern
A Uniform Coding Structure
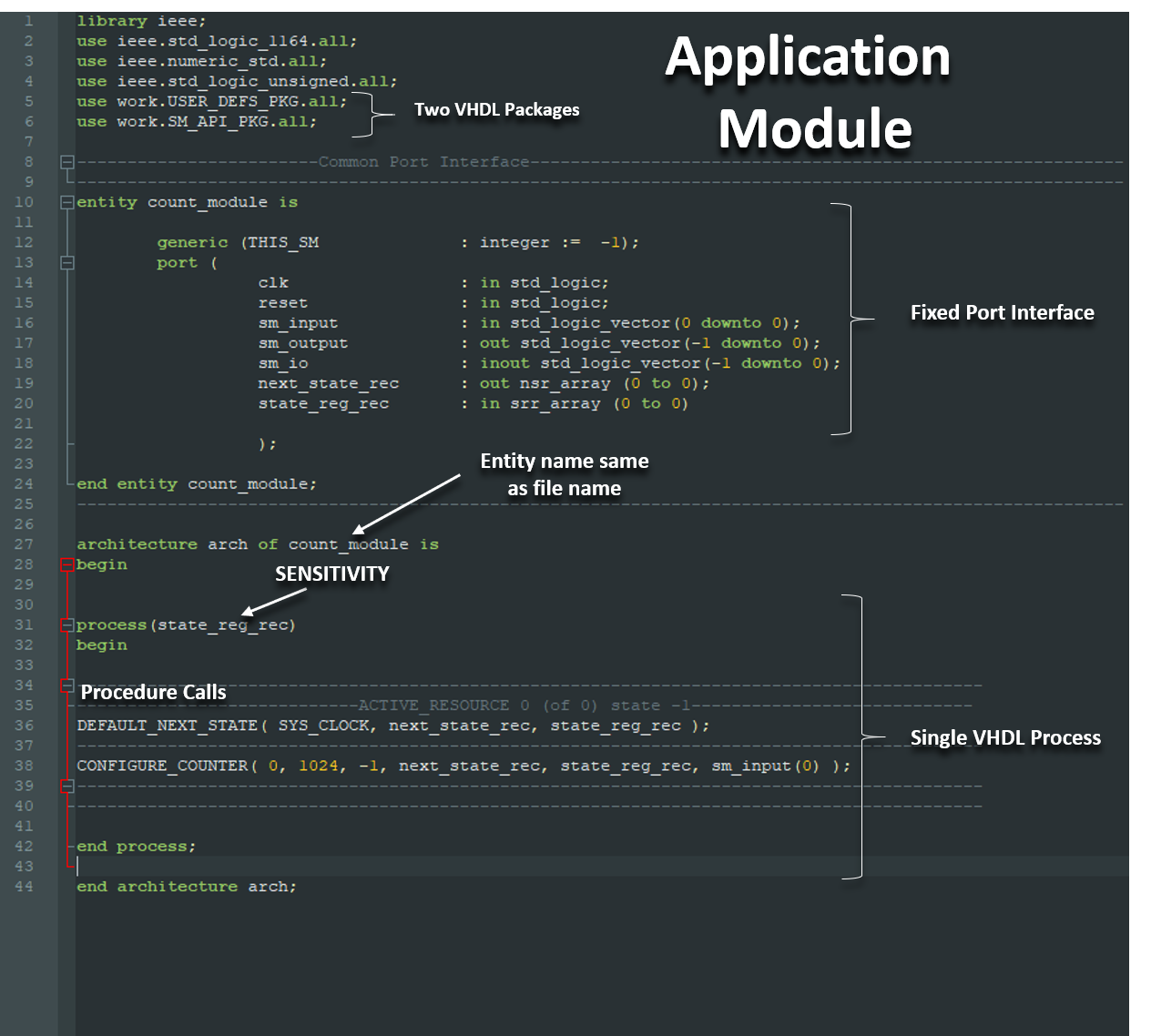
- Functionality of the design pattern are brought to the developer through the use of two non standard VHDL packages
- The entity name is required to match the VHDL file name
- The VHDL sensitivyt list is sensitive to the state register
- In general there will only be a single VHDL process per file
Added Value
</aside>
</section> <section> <header class="justify-content-center banner-header theme-outline" dx-block="block">
Creating an API for FPGA Hardware Development
Strategy for API Development
Our challenge in trying to a creating a useable API for FPGA hardware development is threefold:
- Understand the synthesizable HDL language features we have at our disposal
- Organize the data structures that we create in such a way that the end user can become the most productive
- Create procedure calls based on operations that can be used as building blocks in system design
Because, creating an API is more of an art than a science, there will be instances where we could approach our data structuring in multiple ways. Since our overall goal is to be come more productive FPGA developers, we describe the strategy we use for creating the API for our design pattern.
- Treat everything as a synchronous state machine
- Ensure the default behavior is the most useful behavior
- Prefer indexing an array over a creating a new signal
- Use aliases for readability
-
Use integer data types for index, count, and state
- Have productivity come for free
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside>
Everything Is A Synchronous State Machine
To motivate our rationale as to why we should treat an application module as a state machine, let's start with an example where an application module has exactly one input pin that is used as the count enable to a framework counter.
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex flex-row align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex flex-row align-items-center aside-xxx">
Added Value
</aside>
The Default Behavior Should Be the Most Useful Behavior
When creating our API, using default arguments, we try to prevent things like flatlining from happening. That being said, lets take another look at the 'configure_counter' procedure call and this time lets imagine we forgot to wire sm_input(0) to the last parameter.
If we were to compile and simulate the design, the code may not work as desired, but the counter would still do something. We would see it free running and rolling over as it counts from 0 to 1023. Once we see this, it will be easy to know what we should fix. That behavior occurs because our choice was to make the default value for the count_en to be '1', and the default value for the rollover_en to be '1'.Continuing with our design pattern strategy to treat 'everything as a state machine', the default state of every hardware component inferred by procedure call is made up of two parts:
Added Value
</aside>
- The default values of the procedure call optional arguments (if any)
- The framework default values set by the 'default_next_state' procedure call.
Added Value
</aside>
Prefer Indexing an Array Over a Creating a New Signal
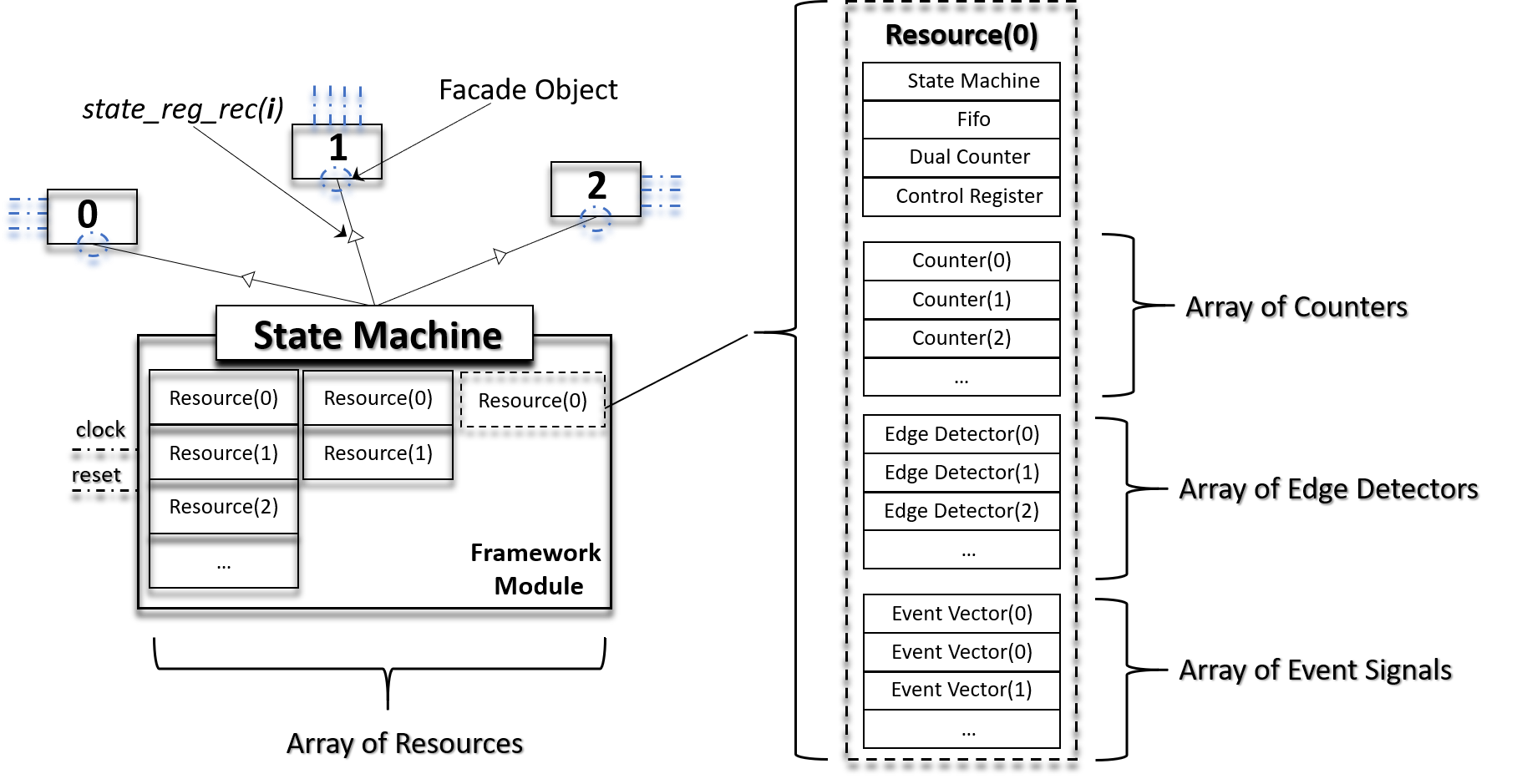
- A single state machine
- A single fifo (receive buffer)
- A single control register
- An array of counters
- An array of edge detectors
- Framework crossbar logical circuitry (synchronous)
When developing the API, the decision to make both state_reg_rec and counter arrays had mostly to do with how to handle some implementation details on the framework side. Using an array data type gives us flexibility on the number of components we can create inside the framework module using the same looping structure. On the application module side, using arrays also gives us the flexibility of generating as many state registers or as many counters as we would like. The one drawback, however, is that it leads to a state register signal that has a long signal name.
Over all, the benefits of having the capability of generating more hardware outweighs the minor drawback of creating longer names. Given a choice, we should prefer to index an array data structure rather then creating a new signal name.
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside>
Alias is Your Friend
Added Value
</aside>
Integer Index, Count, and State
Added Value
</aside>
Looking at the third parameter, we have set the transition state to -1. The meaning of -1 in this context is we wish for the counter to just count, but not 'do anything' when the counter expires. Because the state machine states have the integer data type, we 'could' on the other hand, configure a state machine to change state when the rollover occurs.
Added Value
</aside>
Productivity Should Come For Free
- You don't see clock or reset being used
- You don't see a signal declaration
- You don't see an 'if-then-else' statement
When a counter resets, shouldn't the count go to zero? When it increments, wouldn't it be on the rising edge? Since the motivation for our design pattern is to increase design productivity, we should not have to write extra code to specify some assumed operation. If its expected behavior, you should get that for free.
Another productivity enhancing byproduct that occurs when using the design pattern, is a substantial decrease in the number of 'infrastructure related signals' you need to declare. A while back in our discussion, we mentioned that the data structures that are used by the design pattern were large and that how the long names can be annoying. But here is the up side. Those long state_reg_rec signal names come from the framework as an input to the application module port. That means we get access to a large data structure that we did not need to declare as a signal in our code. We can just start coding our application module and pick off the portions of the state register that we would like to use and start using them. Any portions of state register we use gets kept, and the rest of the large data structure just gets synthesized away.
Added Value
</aside>
The takeaway here is that, the use of the API calls to infer hardware from the framework is optional. Productivity from infrastructure reuse happens when an application module can take advantage of the design pattern handing a general case not every specific use case. Once a VHDL entity conforms to the fixed port interface and becomes an application module, that module gets access to framework resources whether it uses them or not. If the application module chooses to use API calls to infer hardware, it is essentially productivity that the module gets for free.
Added Value
</aside>
</section> <section>
Logical Interconnection
Synchronous Communication Between Application Modules
Back when we made our modifications to the software version of the facade design pattern, we added the ability to logically identify each application module by use of an integer. Without delving into all the details, this is how the logical identifier comes into play.
-
Point to Point Communication (Data Channel)
⇄ Fifo Communication
⇄ Data Exchange Register - Shared Control Register (Control Channel)
- Event Broadcasting
Added Value
</aside>
Point to Point Data Path Communication
Fifo Communication
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside> <aside class="d-flex align-items-center aside-xxx">
Added Value
</aside>
Data Exchange Register
Added Value
</aside>
Shared Control Register
Added Value
</aside>
Event Broadcasting
In general, using 'if statements' are frowned upon when using the design pattern. Because of this, when a transition is needed in response to an event, to make the intent clear, the design pattern has specific API calls to raise and/or event or respond to an event.
Added Value
</aside>
</section> <section>
Simulating for the Design Pattern
Productivity While Testing
In order to simulate an FPGA design that uses our design pattern, we have essentially two options.
- Use a testbenches file to instantiate the top level design and drive application module I/O pins with the testbench file
- Use a testbenches file to instantiate the top level and drive signals internally from the API
Added Value
</aside>
</section>
</article> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.1/dist/js/bootstrap.bundle.min.js"></script> <script src="assets/js/bss_custom_js.js"></script> <script src="https://unpkg.com/@bootstrapstudio/bootstrap-better-nav/dist/bootstrap-better-nav.min.js"></script> </body>
</html>